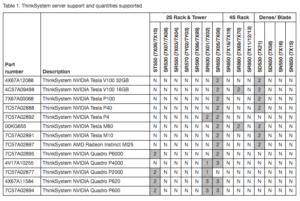
Lenovo ThinkSystem servers support GPU technology to accelerate different computing workloads, maximize performance for graphic design, virtualization, artificial intelligence and high performance computing applications in Lenovo servers.
The following table summarizes the server support for the GPUs. The numbers listed in the server columns represent the number of GPUs supported.
GroundBreaking Volta Architecture
By pairing CUDA Cores and Tensor Cores within a unified architecture, a single server with Tesla V100 GPUs can replace hundreds of commodity CPU servers for traditional HPC and Deep Learning. TENSOR CORE Equipped with 640 Tensor Cores, Tesla V100 delivers 125 TeraFLOPS of deep learning performance. That’s 12X Tensor FLOPS for DL Training, and 6X Tensor FLOPS for DL Inference when compared to NVIDIA Pascal™ GPUs.
Next Generation NVLink
NVIDIA NVLink in Tesla V100 delivers 2X higher throughput compared to the previous generation. Up to eight Tesla V100 accelerators can be interconnected at up to 300 GB/s to unleash the highest application performance possible on a single server. HBM2 With a combination of improved raw bandwidth of 900 GB/s and higher DRAM utilization efficiency at 95%, Tesla V100 delivers 1.5X higher memory bandwidth over Pascal GPUs as measured on STREAM.
Maximum Efficiency Mode
The new maximum efficiency mode allows data centers to achieve up to 40% higher compute capacity per rack within the existing power budget. In this mode, Tesla V100 runs at peak processing efficiency, providing up to 80% of the performance at half the power consumption.
Programmability
Tesla V100 is architected from the ground up to simplify programmability. Its new independent thread scheduling enables finer-grain synchronization and improves GPU utilization by sharing resources among small jobs.
CUDA Ready
CUDA® is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, developers are able to dramatically speed up computing applications by harnessing the power of GPUs.
In GPU-accelerated applications, the sequential part of the workload runs on the CPU – which is optimized for single-threaded performance – while the compute intensive portion of the application runs on thousands of GPU cores in parallel. When using CUDA, developers program in popular languages such as C, C++, Fortran, Python and MATLAB and express parallelism through extensions in the form of a few basic keywords.
The CUDA Toolkit from NVIDIA provides everything you need to develop GPU-accelerated applications. The CUDA Toolkit includes GPU-accelerated libraries, a compiler, development tools and the CUDA runtime.
Performance Specifications for NVIDIA Tesla P4, P40 and V100 Accelerators
|
Tesla V100: The Universal Datacenter GPU |
Tesla P4 for Ultra-Efficient Scale-Out Servers |
Tesla P40 for Inference Throughput Servers |
| Single-Precision Performance (FP32) |
14 teraflops (PCIe)
15.7 teraflops (SXM2) |
5.5 teraflops |
12 teraflops |
| Half-Precision Performance (FP16) |
112 teraflops (PCIe)
125 teraflops (SXM2) |
— |
— |
| Integer Operations (INT8) |
— |
22 TOPS* |
47 TOPS* |
| GPU Memory |
16/32 GB HBM2 |
8 GB |
24 GB |
| Memory Bandwidth |
900 GB/s |
192 GB/s |
346 GB/s |
| System Interface/Form Factor |
Dual-Slot, Full-Height PCI Express Form Factor
SXM2 / NVLink |
Low-Profile PCI Express Form Factor |
Dual-Slot, Full-Height PCI Express Form Factor |
| Power |
250W (PCIe)
300W (SXM2) |
50 W/75 W |
250 W |
| Hardware-Accelerated Video Engine |
— |
1x Decode Engine, 2x Encode Engines |
1x Decode Engine, 2x Encode Engines |
*Tera-Operations per Second with Boost Clock Enabled













Reviews
There are no reviews yet.